无聊浏览某漫画网站(你懂的。-_-),每次翻页时都需要重新请求整个页面,页面杂七杂八的内容过多,导致页面加载过程耗时略长。于是决定先把图片先全部保存到本地。本文的主要内容,就是讲解如何通过一个爬虫程序,自动将所有图片抓取到本地。
先来看网页大概张什么样。:)
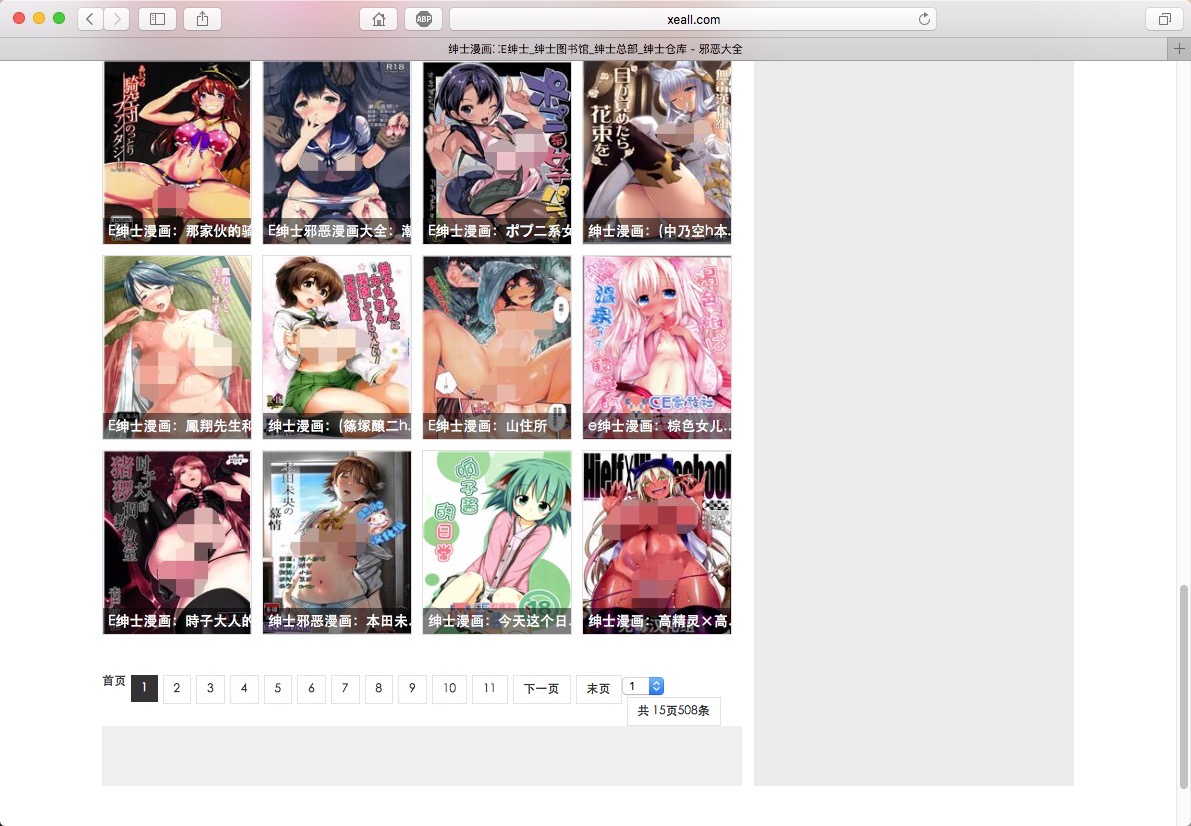
漫画封面列表界面:
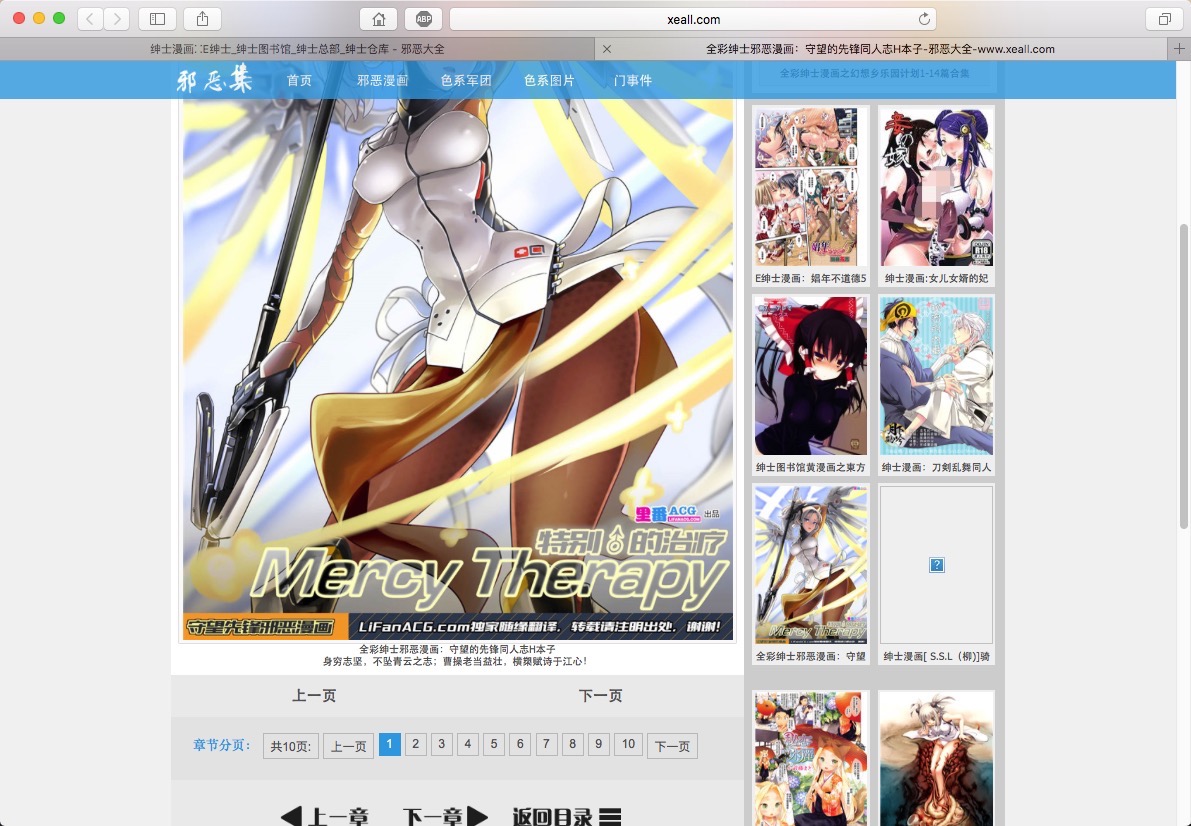
每部漫画点击进去的界面
漫画列表每一页有几十部漫画,网站暂时有15页列表,每部漫画页数有10+页到近200页不等,所以所有漫画包含的图片总数还是比较可观的,通过手动将每张图右键另存基本不可能完成。接下来将一步一步展示,如何用Python实现一个简单爬虫的程序,将网页上所有漫画全保存到本地。Python用的是2.7版本。
首先,何为网络爬虫?
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
一般而言,简单的爬虫实现主要分为两步:
- 获取指定网页html源码;
- 通过正则表达式提取出源码中的目标内容。
本文程序实现大体步骤:
- 获取每页漫画列表的url;
- 获取每页漫画列表中每一部漫画的url;
- 获取每部漫画每一页图片的url;
- 通过图片的url将图片保存到本地。
(总之就是通过for循环遍历的过程。)
最后会附本文Demo完整源码。
获取每页漫画列表的url
程序最开始处理的页面为:http://www.xeall.com/shenshi,即漫画列表的首页。绅士,你懂的。。
先创建一个文件Gentleman.py,引入需要用到的库:
#coding:utf-8
import urllib2
import re
import os
import zlib
定义一个类,和初始化函数:
class Gentleman:
def __init__(self, url, path):
exists = os.path.exists(path)
if not exists:
print "文件路径无效."
exit(0)
self.base_url = url
self.path = path
url为漫画列表首页url
path为图片保存在本地的路径,做个错误检测,判断本地是否存在对应的路径
接下来定义 get_content 方法,获取指定url的html源码内容:
def get_content(self, url):
# 打开网页
try:
request = urllib2.Request(url)
response = urllib2.urlopen(request, timeout=20)
# 将网页内容解压缩
decompressed_data = zlib.decompress(response.read(), 16 + zlib.MAX_WBITS)
# 网页编码格式为 gb2312
content = decompressed_data.decode('gb2312', 'ignore')
# print content
return content
except Exception, e:
print e
print "打开网页: " + url + "失败."
return None
urllib2.Request() 通过指定的url构建一个请求,urllib2.urlopen() 获取请求返回的结果,timeout设为20秒无响应则做超时处理。urllib2.urlopen() 有可能出现打开网页错误的情况,所以做了异常处理,保证在返回40X、50X之类的时候程序不会退出。后续相关的操作也都会做异常的处理。
原网页为压缩过的,请求到之后必须先进行解压缩处理。
通过 charset=gb2312 可知解码所需格式。
判断网页是否为压缩的编码类型,可以通过打印语句:
response.info().get('Content-Encoding')
打印结果为:
'gzip'
函数的返回结果为页面html源码文本。
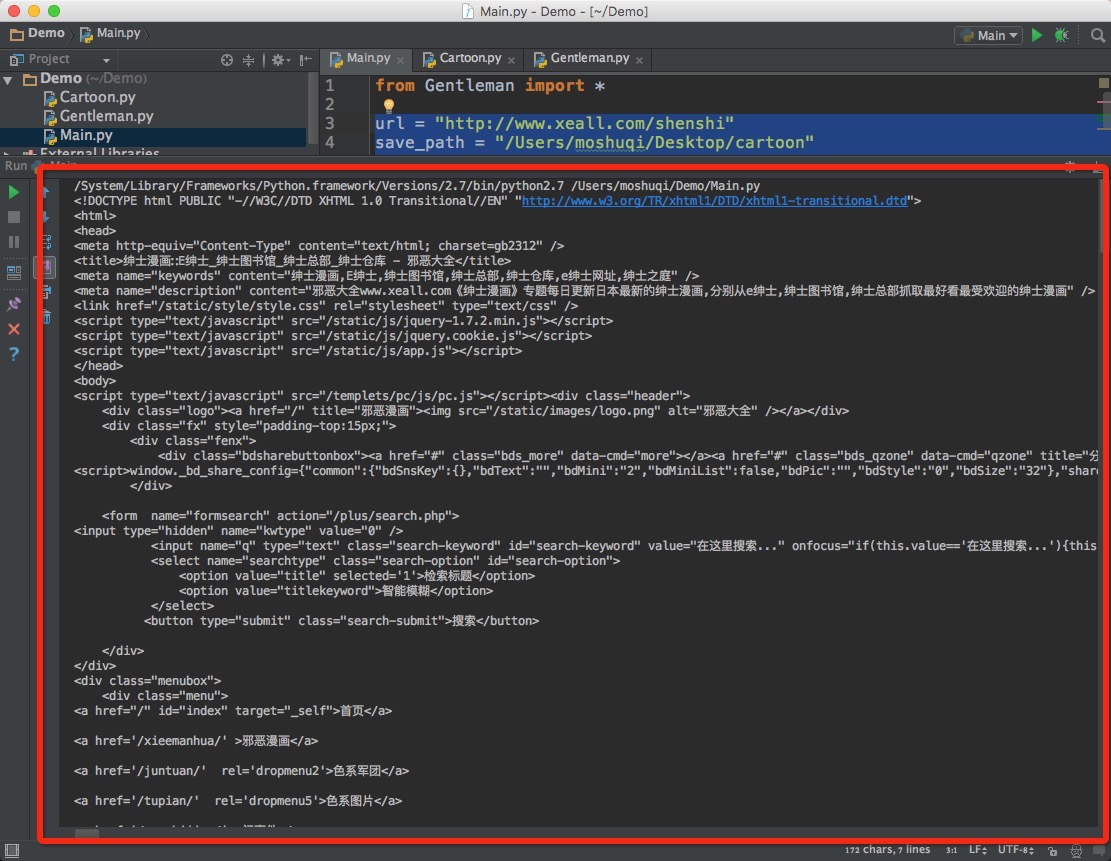
跑起来试试:
url = "http://www.xeall.com/shenshi"
save_path = "/Users/moshuqi/Desktop/cartoon"
gentleman = Gentleman(url, save_path)
content = gentleman.get_content(url)
print content
可以看到打印结果:
接下来分析源码文件,看如何从中获取到每一页漫画列表的url。
页面上有个选择页的控件:
通过分析对应控件的源码,可知具体每一页所对应的url:
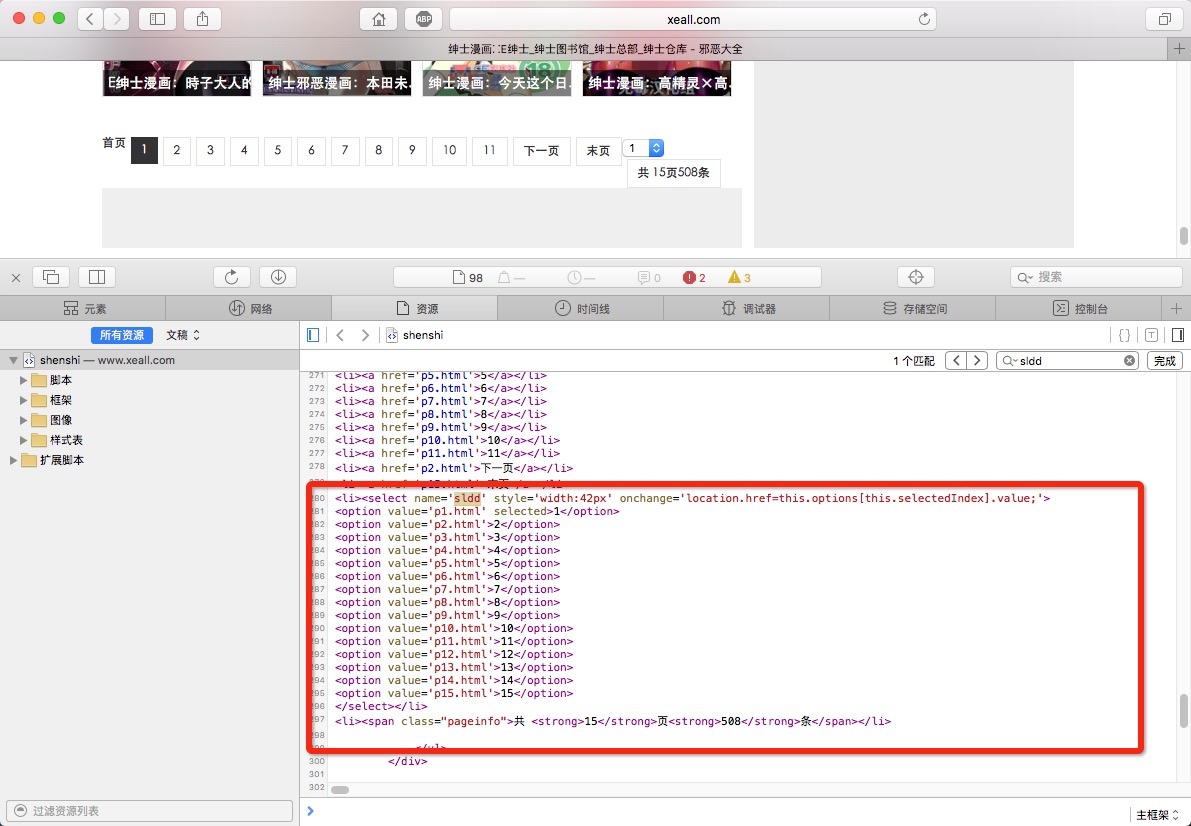
控件的 name 为 sldd ,通过搜索全文发现只有这一处“sldd”字段,所以该字段可用来做标识。
option value 的值即为对应页的url。
定义 get_page_url_arr 方法,获取每一页的url,返回一个数组:
def get_page_url_arr(self, content):
pattern = re.compile('name=\'sldd\'.*?>(.*?)</select>', re.S)
result = re.search(pattern, content)
option_list = result.groups(1)
pattern = re.compile('value=\'(.*?)\'.*?</option>', re.S)
items = re.findall(pattern, option_list[0])
arr = []
for item in items:
page_url = self.base_url + '/' + item
arr.append(page_url)
print "total pages: " + str(len(arr))
return arr
传入的 content 为页面源码,首先通过 sldd 获取到其中 option 的内容。采用正则表达式将内容提取出来。(关于正则表达式,不熟悉的同学推荐看这本 【正则表达式必知必会】,很薄的一本书,半天时间大概翻一遍基本就能用来处理大部分常见问题了)
正则表达式用了Python re模块,具体方法的使用请自行百度, 这里只大概说一下思路。
首先用到的匹配模式:
'name=\'sldd\'.*?>(.*?)</select>'
' 为 ‘ 的转义字符,匹配先找到以 name=’sldd’ 开头的字符,.?** 是一个非贪婪匹配,用来匹配 **name=’sldd’** 之后到最近的一个 **>** 之间的内容。**(.?) 意义和前一个类似,加上 () 表示为分组,可以在匹配结果中访问,即我们需要识别出的内容。结尾的 select 标签即为识别内容最后的标记。
运行后 option_list 识别到的内容应为:
<option value='p1.html' selected>1</option>
<option value='p2.html'>2</option>
<option value='p3.html'>3</option>
<option value='p4.html'>4</option>
<option value='p5.html'>5</option>
<option value='p6.html'>6</option>
<option value='p7.html'>7</option>
<option value='p8.html'>8</option>
<option value='p9.html'>9</option>
<option value='p10.html'>10</option>
<option value='p11.html'>11</option>
<option value='p12.html'>12</option>
<option value='p13.html'>13</option>
<option value='p14.html'>14</option>
<option value='p15.html'>15</option>
再正对 option_list 的内容进行识别,获取到每个 option 的值,匹配模式为:
'value=\'(.*?)\'.*?</option>'
取到的值和一开始 base_url 连接拼接起来即为每一页的url。
测试一下:
arr = gentleman.get_page_url_arr(content)
print arr
打印结果:
[u'http://www.xeall.com/shenshi/p1.html', u'http://www.xeall.com/shenshi/p2.html', u'http://www.xeall.com/shenshi/p3.html', u'http://www.xeall.com/shenshi/p4.html', u'http://www.xeall.com/shenshi/p5.html', u'http://www.xeall.com/shenshi/p6.html', u'http://www.xeall.com/shenshi/p7.html', u'http://www.xeall.com/shenshi/p8.html', u'http://www.xeall.com/shenshi/p9.html', u'http://www.xeall.com/shenshi/p10.html', u'http://www.xeall.com/shenshi/p11.html', u'http://www.xeall.com/shenshi/p12.html', u'http://www.xeall.com/shenshi/p13.html', u'http://www.xeall.com/shenshi/p14.html', u'http://www.xeall.com/shenshi/p15.html']
获取每一页包含的漫画的url
例如,先对第一页做处理http://www.xeall.com/shenshi/p1.html
打开网页,找到这部分所对应的源码:
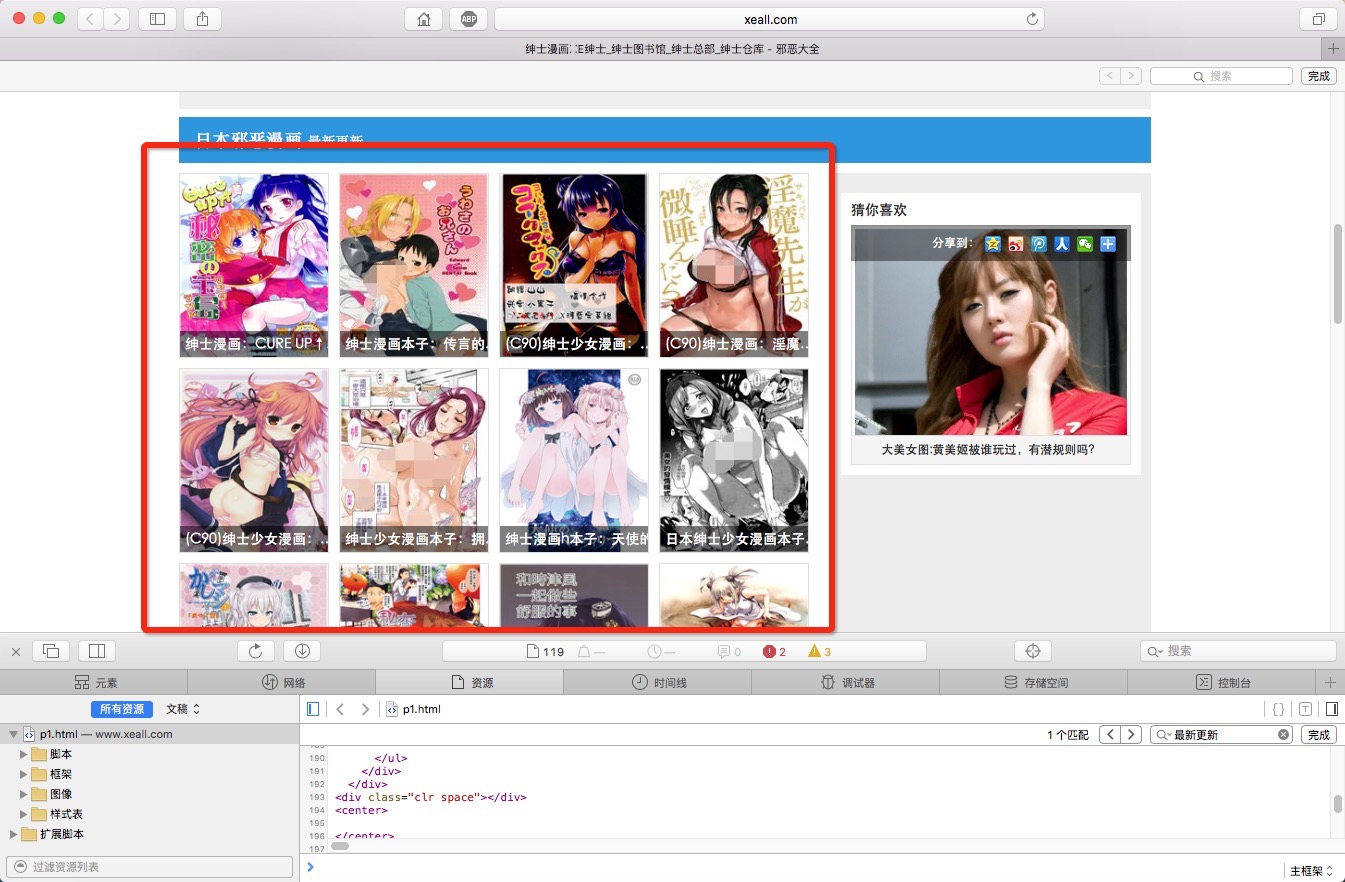
浏览器上展示这部分的源码很长,而且没有换行,我们可以将文本拷贝到本地的编辑器上再进行分析。
可以看到内容比较长,以下两张图分别是开头和结尾的截图,红色圈出的内容可作为识别这段文本的开头和结尾。
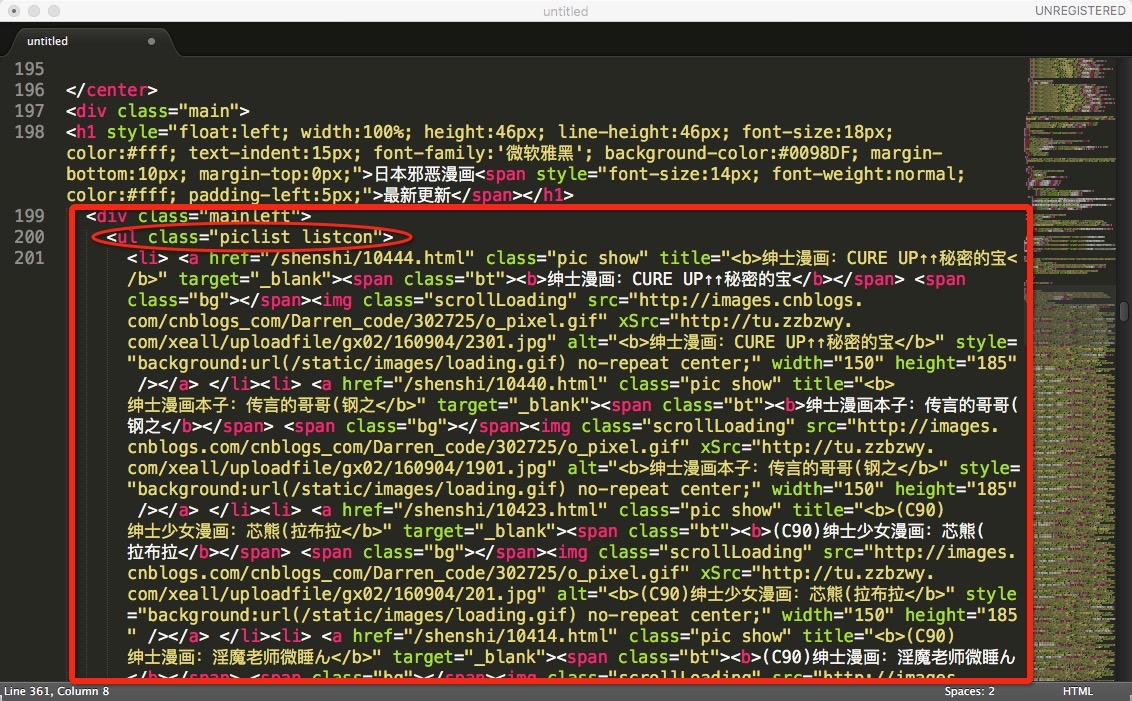
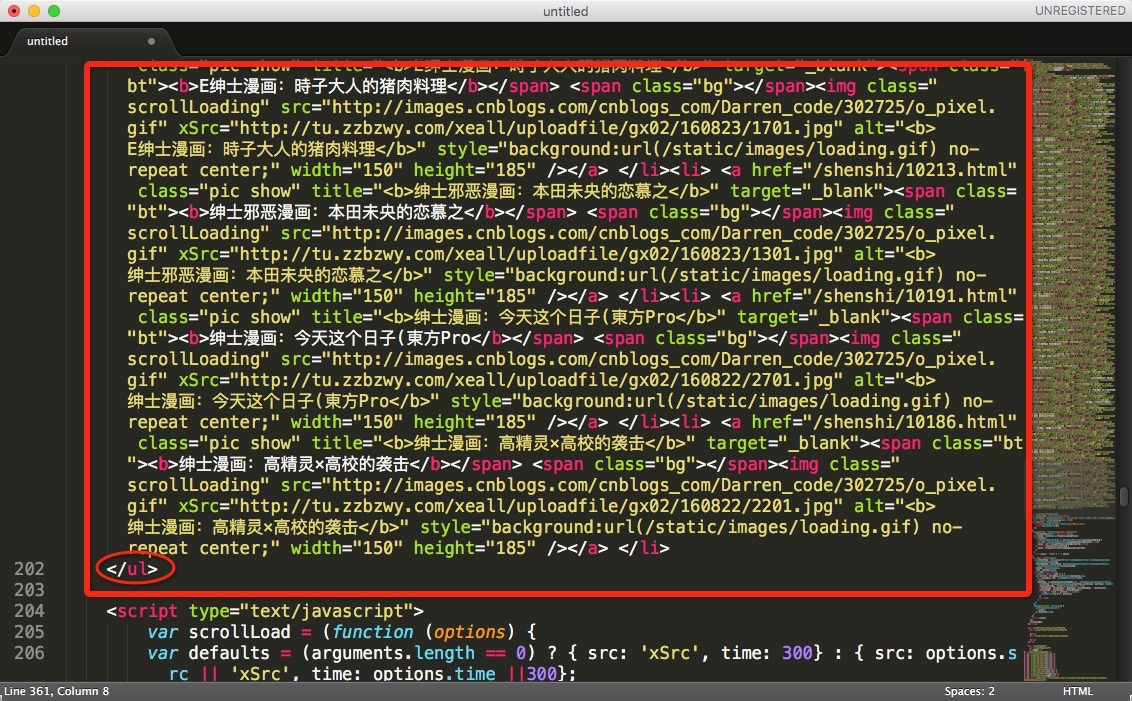
定义 get_cartoon_arr 方法,获取每一页包含的漫画的url,返回一个数组:
def get_cartoon_arr(self, url):
content = self.get_content(url)
if not content:
print "获取网页失败."
return None
pattern = re.compile('class="piclist listcon".*?>(.*?)</ul>', re.S)
result = re.search(pattern, content)
cartoon_list = result.groups(1)
pattern = re.compile('href="/shenshi/(.*?)".*?class="pic show"', re.S)
items = re.findall(pattern, cartoon_list[0])
arr = []
for item in items:
# print item
page_url = self.base_url + '/' + item
arr.append(page_url)
return arr
匹配模式:
'class="piclist listcon".*?>(.*?)</ul>'
识别出漫画列表的内容,内容太多就不打印了。
下图为每一部漫画所包含的信息,例如展示的第一部漫画为圈出的部分。
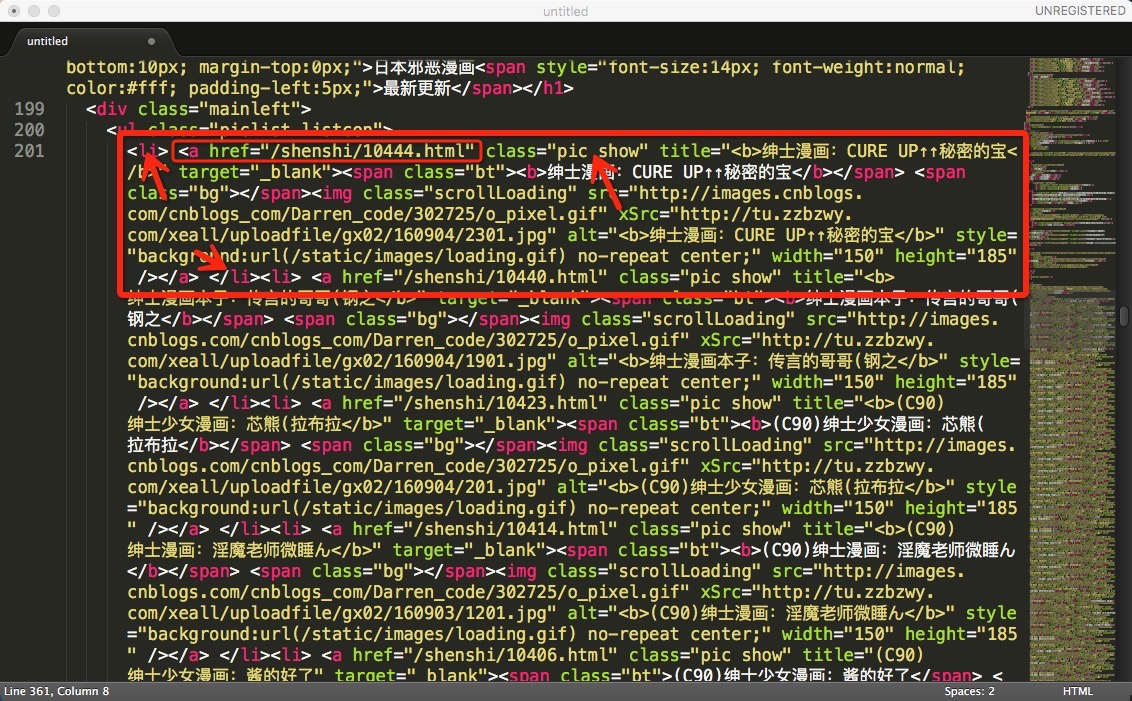
我们只需要提取到 href 中的信息,可以分别用 /shenshi/ 和 class=”pic show” 作为开头结尾,提取出 “10444.html” 链接信息。
匹配模式为:
'href="/shenshi/(.*?)".*?class="pic show"'
将提取的结果和 base_url 连接拼接起来即为漫画的url。
测试代码:
arr = gentleman.get_cartoon_arr("http://www.xeall.com/shenshi/p1.html")
print arr
打印结果:
[u'http://www.xeall.com/shenshi/10444.html', u'http://www.xeall.com/shenshi/10440.html', u'http://www.xeall.com/shenshi/10423.html', u'http://www.xeall.com/shenshi/10414.html', u'http://www.xeall.com/shenshi/10406.html', ...]
创建Cartoon类
用来专门处理每一部漫画的类,要处理的细节较多,所以专门封装成一个类来实现。
类的初始化函数,参数 url 为漫画地址
#coding:utf-8
import urllib2
import re
import zlib
import os
class Cartoon:
def __init__(self, url):
self.base_url = "http://www.xeall.com/shenshi"
self.url = url
Cartoon类中也会包含 get_content 函数,和之前的实现方式一样,这里就不列出来了。当然,好的实现方式应该避免重复代码,我懒得整理直接拷过来了。- -
定义获取漫画名的方法 get_title ,因为漫画名后面要用来作为保存每部漫画的文件夹名称。
def get_title(self, content):
pattern = re.compile('name="keywords".*?content="(.*?)".*?/', re.S)
result = re.search(pattern, content)
if result:
title = result.groups(1)
return title[0]
else:
print "获取标题失败。"
return None
我们用这部漫画做测试http://www.xeall.com/shenshi/10444.html
测试代码:
title = cartoon.get_title(content)
print title
打印结果:
绅士漫画:CURE UP↑↑秘密的宝岛 (魔法少女同人志)
接下来需要获取到翻页对应的url,翻页部分见下图:
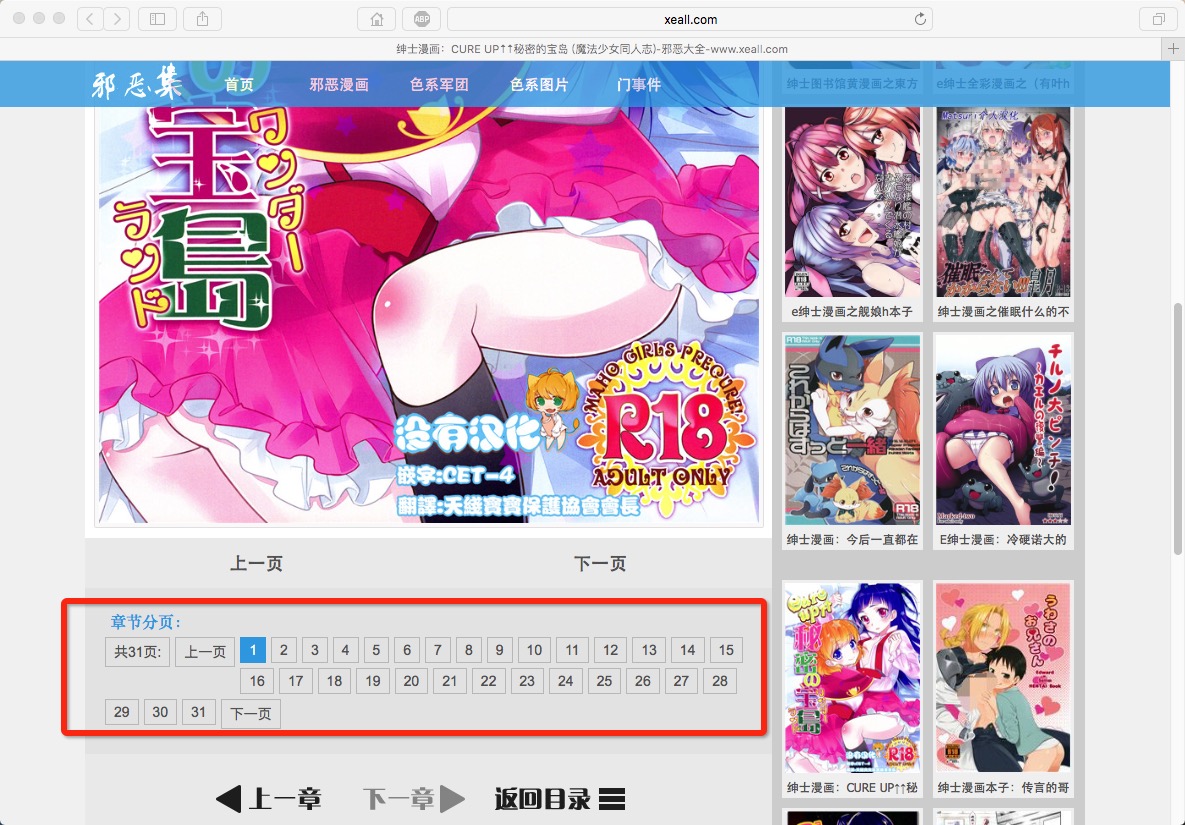
定义获取漫画每一页的url方法 get_page_url_arr
def get_page_url_arr(self, content):
pattern = re.compile('class="pagelist">(.*?)</ul>', re.S)
result = re.search(pattern, content)
page_list = result.groups(1)
pattern = re.compile('<a href=\'(.*?)\'>.*?</a>', re.S)
items = re.findall(pattern, page_list[0])
arr = []
for item in items:
page_url = self.base_url + "/" + item
arr.append(page_url)
# pagelist中还包含了上一页和下一页,根据网页格式可知分别在开始和结束,所以去掉首尾元素避免重复
arr.pop(0)
arr.pop(0)
arr.pop(len(arr) - 1)
return arr
打开网页源码:
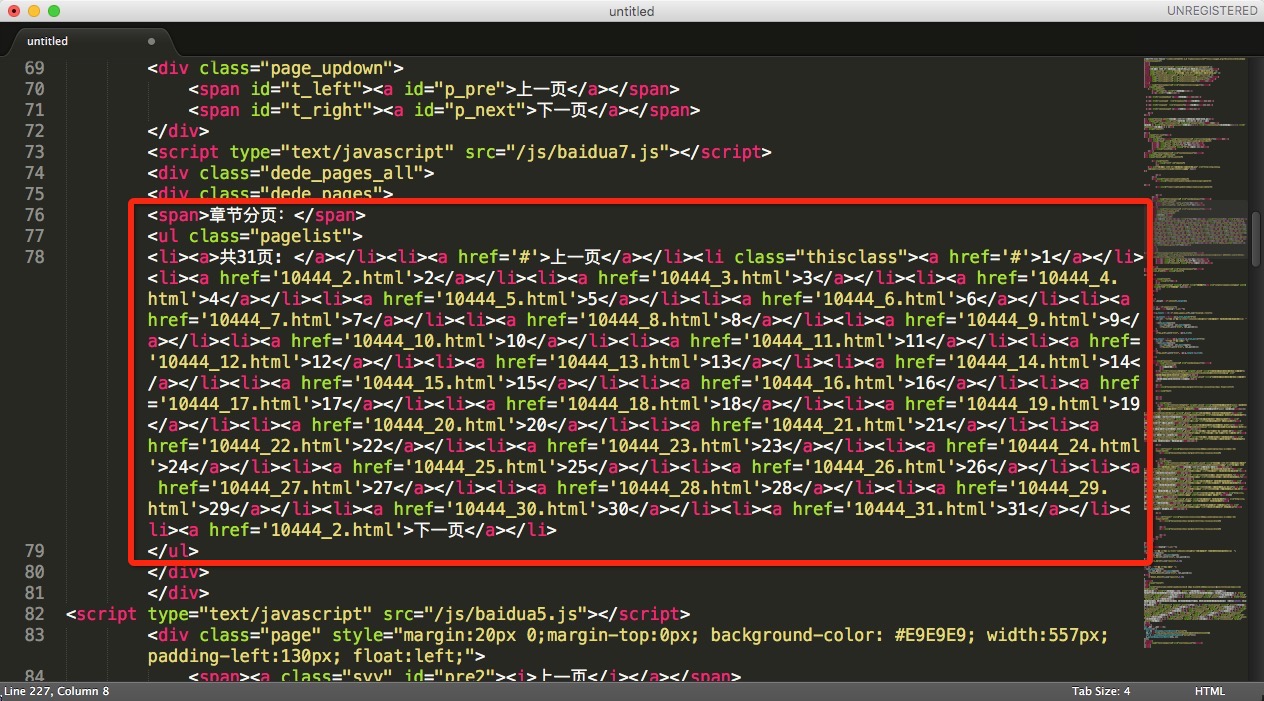
可以看到圈出部分为每一页按钮对应的信息。
通过匹配模式获取到这部分内容;
'class="pagelist">(.*?)</ul>'
对这部分内容进行匹配,获取每一页的url:
'<a href=\'(.*?)\'>.*?</a>'
看下图会发现,前两个链接为 href=’#’ ,最后一个为下一页链接,重复了。
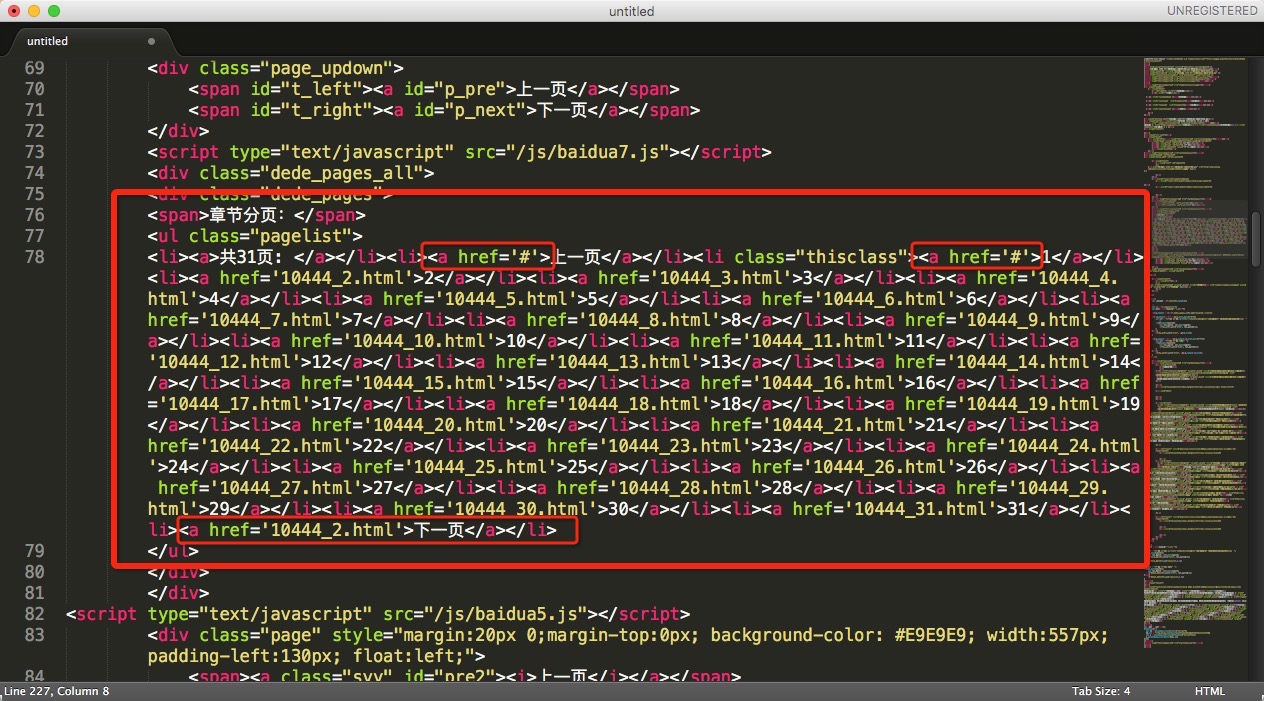
所以得到数组把这3个元素剔除掉。(至于为什么把 href=’#’ 都去掉,因为用这个链接后面会出错,具体原因懒得追究,反正去掉之后也就少了第一页的封面而已。)
arr.pop(0)
arr.pop(0)
arr.pop(len(arr) - 1)
测试代码:
arr = cartoon.get_page_url_arr(content)
print arr
打印结果:
[u'http://www.xeall.com/shenshi/10444_2.html', u'http://www.xeall.com/shenshi/10444_3.html', u'http://www.xeall.com/shenshi/10444_4.html', ...]
获取每页漫画图片的url
例如针对之前获取到数组的第一个元素:http://www.xeall.com/shenshi/10444_2.html
打开网页,查看源码:
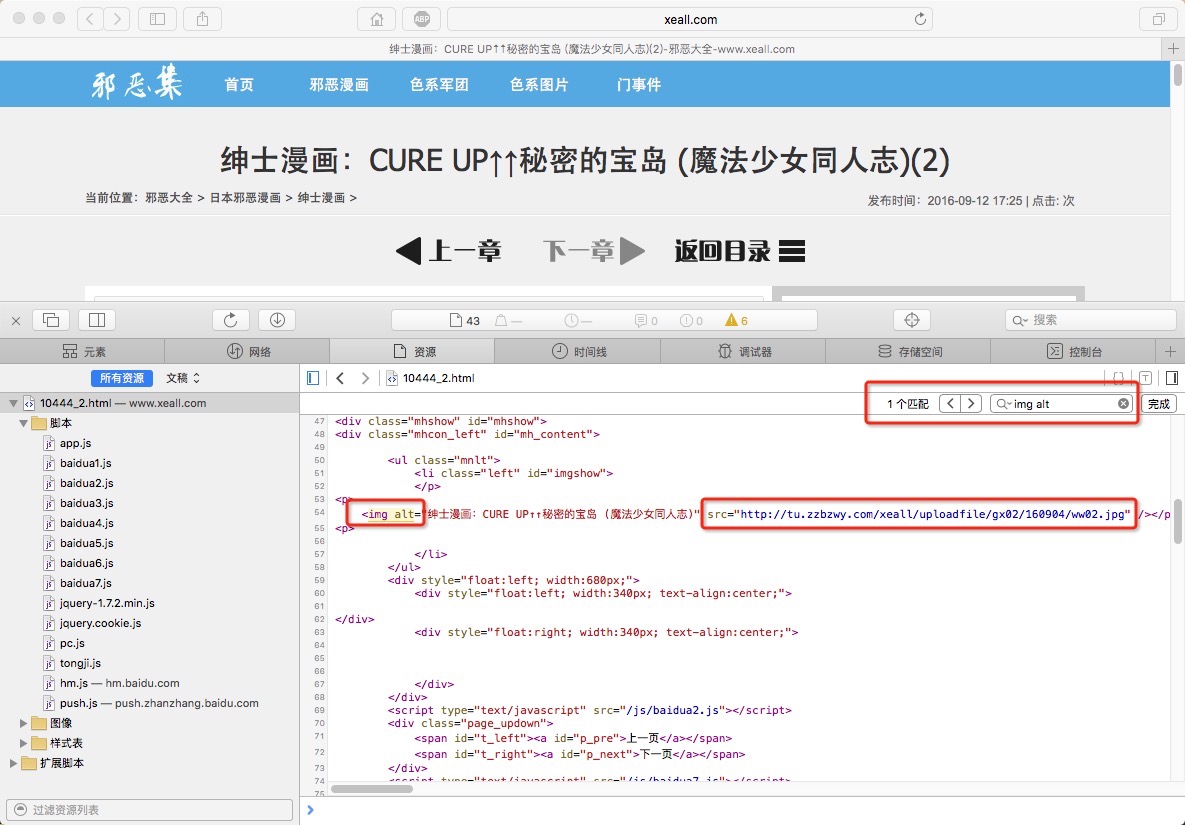
找到页面图片对应的代码,通过搜索 img alt 可知文件中只有一处,所以可以用这个字段用来标识。
定义获取图片url的函数 get_pic_url :
def get_pic_url(self, page_url):
content = self.get_content(page_url)
if not content:
return None
pattern = re.compile('<img alt.*?src="(.*?)".*?/>', re.S)
result = re.search(pattern, content)
if result:
pic = result.groups(1)
return pic[0]
else:
print "获取图片地址失败。"
print "url: " + page_url
return None
匹配模式为:
'<img alt.*?src="(.*?)".*?/>'
这里最初使用了后面的 p 标签结束符作为结束标识,后来发现极少数部分页面用的不是 p 而是 br,因而导致图片url获取失败。
测试代码:
url = cartoon.get_pic_url("http://www.xeall.com/shenshi/10444_2.html")
print url
打印结果:
http://tu.zzbzwy.com/xeall/uploadfile/gx02/160904/ww02.jpg
点击打开看到直接就是一张图片
将图片保存到本地
定义保存函数的方法 save_pic
def save_pic(self, pic_url, path):
req = urllib2.Request(pic_url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36')
req.add_header('GET', pic_url)
try:
print "save pic url:" + pic_url
resp = urllib2.urlopen(req, timeout=20)
data = resp.read()
# print data
fp = open(path, "wb")
fp.write(data)
fp.close
print "save pic finished."
except Exception, e:
print e
print "save pic: " + pic_url + " failed."
pic_url 为图片链接,path 为图片保存到本地的路径。
这遇到了个坑,Request 请求若不设置 User-Agent 信息会导致返回 403 Forbidden,服务器可能对访问做了些限制。
最后Cartoon类定义一个对外的 save 方法,将漫画所有图片保存到本地
def save(self, path):
dir_path = path + "/" + self.title
self.create_dir_path(dir_path)
for i in range(0, len(self.page_url_arr)):
page_url = self.page_url_arr[i]
pic_url = self.get_pic_url(page_url)
if pic_url == None:
continue
pic_path = dir_path + "/" + str(i + 1) + ".jpg"
self.save_pic(pic_url, pic_path)
print self.title + " fetch finished."
给漫画创建创建本地文件夹,文件夹名称为漫画名
def create_dir_path(self, path):
# 以漫画名创建文件夹
exists = os.path.exists(path)
if not exists:
print "创建文件夹"
os.makedirs(path)
else:
print "文件夹已存在"
完成的初始化函数:
def __init__(self, url):
self.base_url = "http://www.xeall.com/shenshi"
self.url = url
content = self.get_content(self.url)
if not content:
print "Cartoon init failed."
return
self.title = self.get_title(content)
self.page_url_arr = self.get_page_url_arr(content)
下载一部完整漫画的测试代码:
url = "http://www.xeall.com/shenshi/10444.html"
save_path = "/Users/moshuqi/Desktop/cartoon"
cartoon = Cartoon(url)
cartoon.save(save_path)
运行起来,看看置顶文件夹结果:
将Cartoon类和Gentlman类结合,爬取所有漫画图片
Gentleman 完整的初始化函数:
def __init__(self, url, path):
exists = os.path.exists(path)
if not exists:
print "文件路径无效."
exit(0)
self.base_url = url
self.path = path
content = self.get_content(url)
self.page_url_arr = self.get_page_url_arr(content)
外部调用的接口方法,遍历所有页和所有漫画:
def hentai(self):
# 遍历每一页的内容
for i in range(0, len(self.page_url_arr)):
# 获取每一页漫画的url
cartoon_arr = self.get_cartoon_arr(self.page_url_arr[i])
print "page " + str(i + 1) + ":"
print cartoon_arr
for j in range(0, len(cartoon_arr)):
cartoon = Cartoon(cartoon_arr[j])
cartoon.save(self.path)
print "======= page " + str(i + 1) + " fetch finished ======="
最终的结果跑起来:
url = "http://www.xeall.com/shenshi"
save_path = "/Users/moshuqi/Desktop/cartoon"
gentleman = Gentleman(url, save_path)
gentleman.hentai()
打印输出:
可以看到置顶的文件夹里不断生成新的漫画文件夹和图片。
图片爬取结果
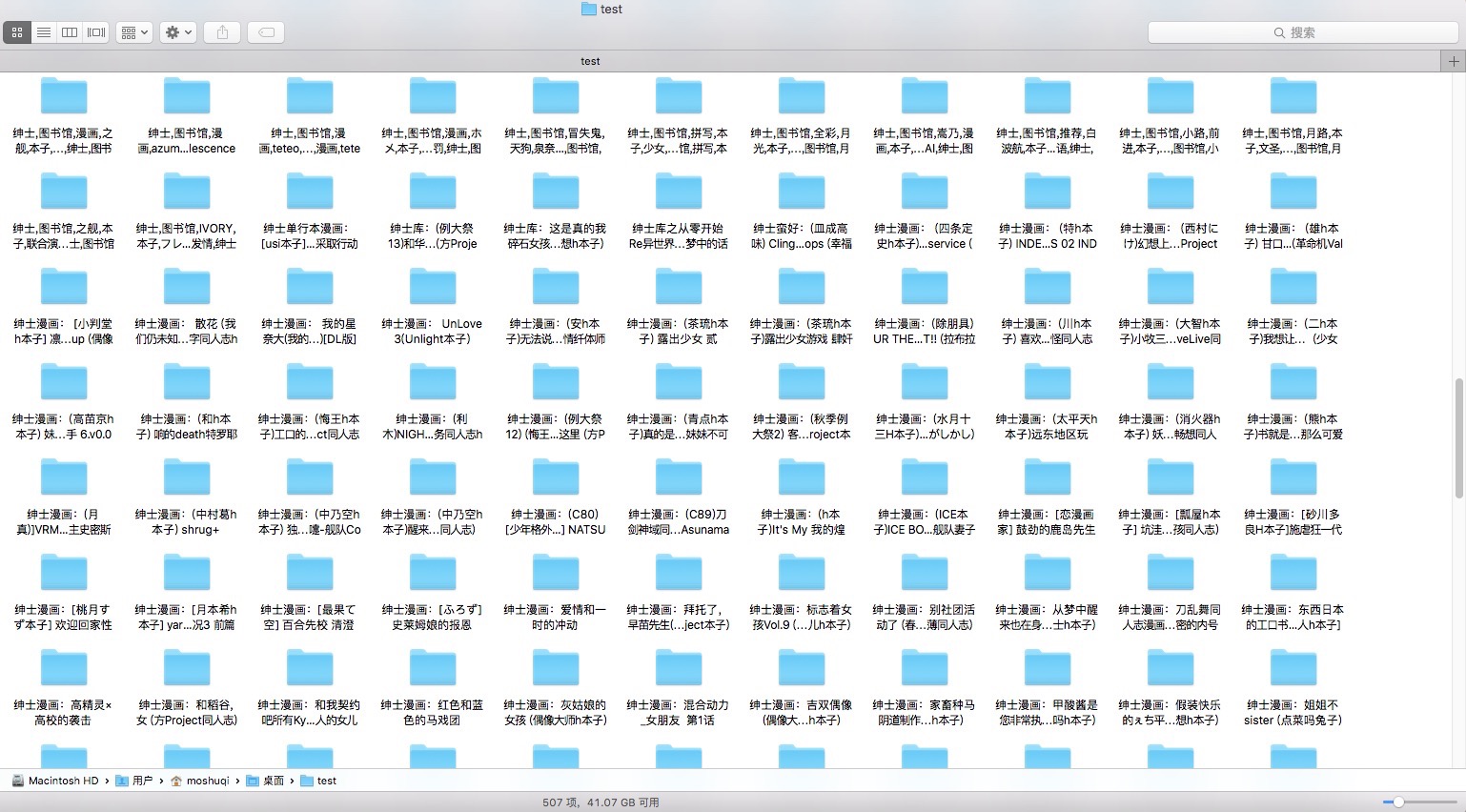
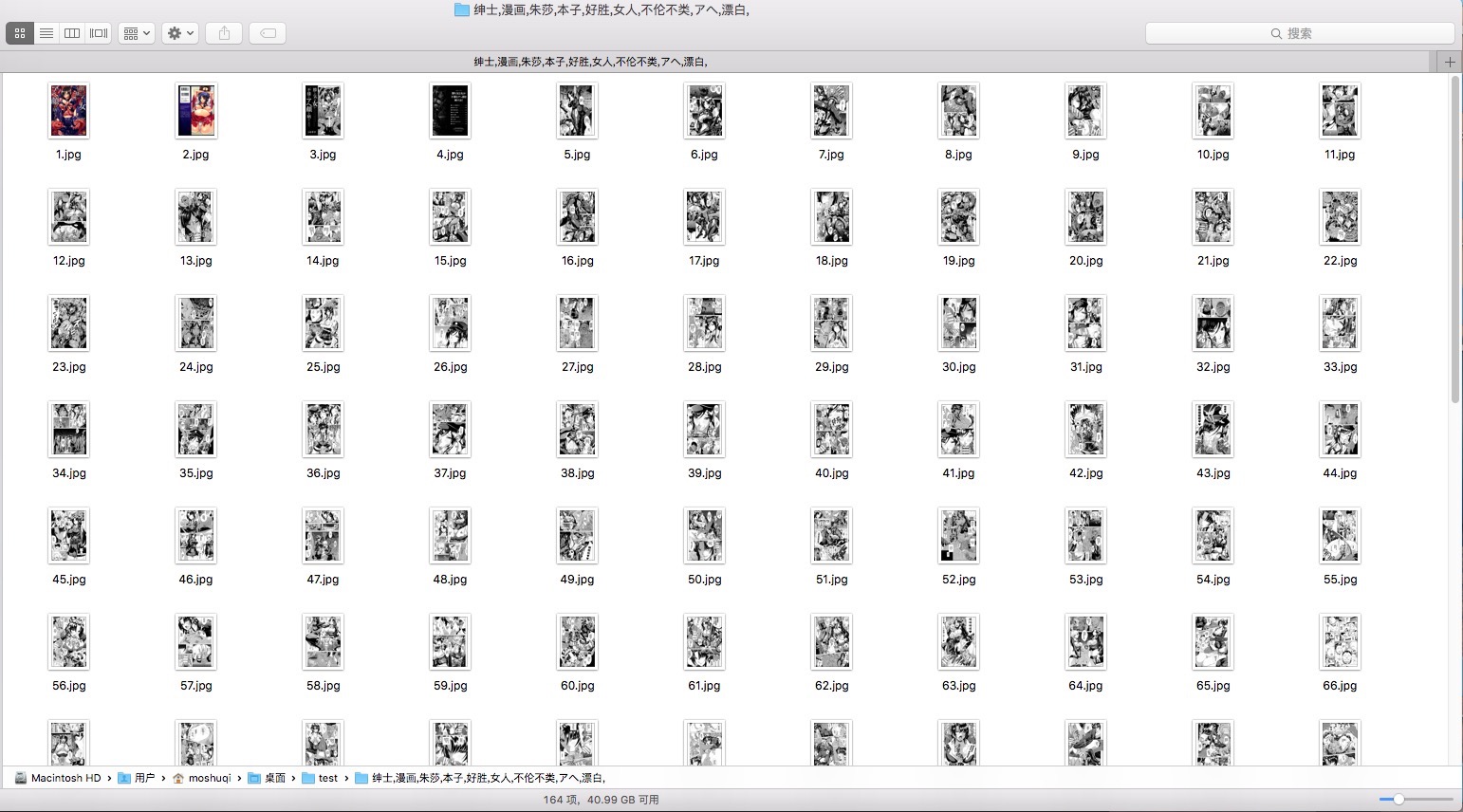
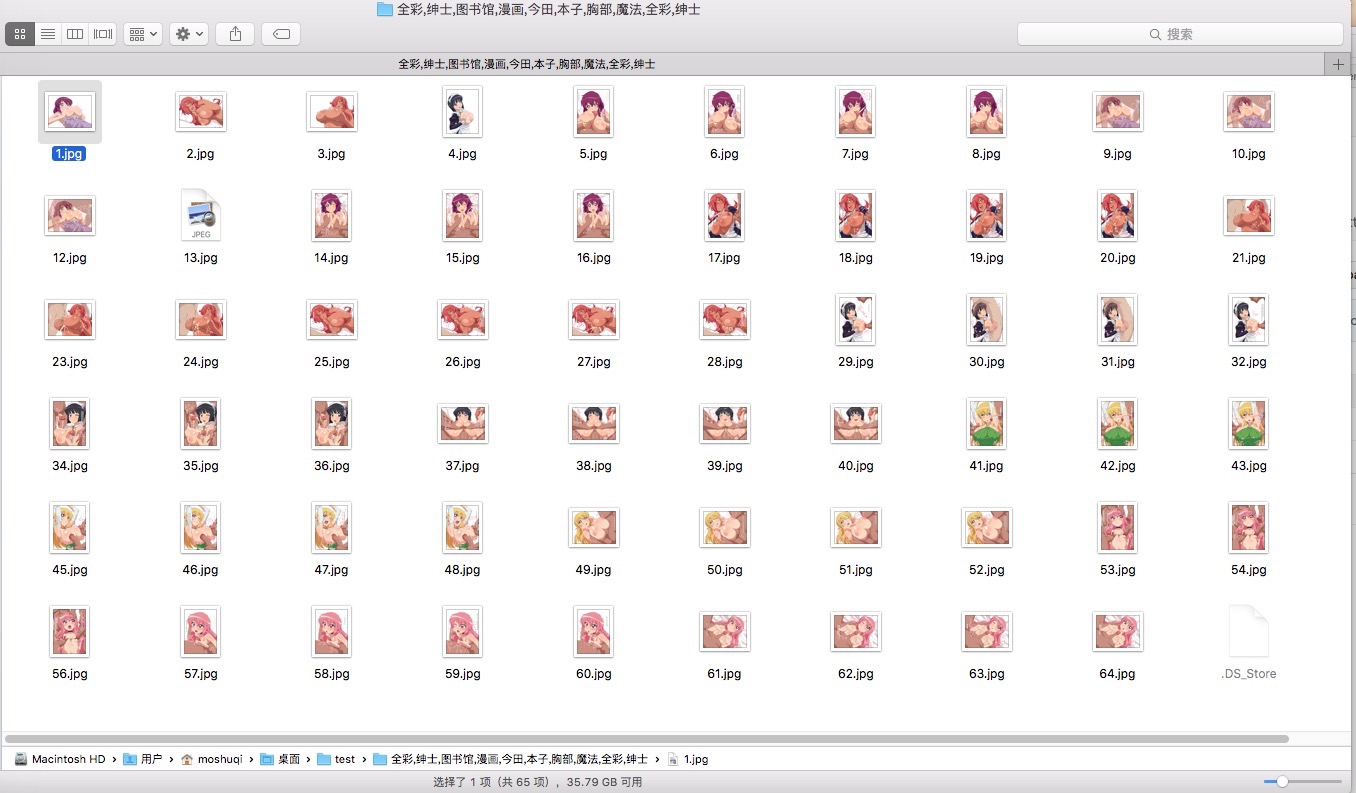
程序连续跑了几个小时,一共抓取500+部漫画,1W5+张图片,文件总大小4G+。大概如上图所示。- -
其他
程序里还做了些其他处理。偶尔会出现图片请求失败,导致一部漫画缺少几页,对于这种情况的漫画做处理时,通过判断只对缺失的页做请求。
重新跑程序时,每部漫画都会先拿服务器上的总页数与本地页数做对比,若大于或等于(为什么不是等于,因为Mac系统会在文件夹里生成.DS_store文件。。)则说明该部漫画已爬取完成,不再重新做处理。
总之就是避免重新运行程序时避免重复数据的爬取。处理在Demo代码里面,已加上注释说明。
最后。
本文只是展示了网络爬虫基本使用的大体思路而已,程序可以优化的地方还很多,如爬取时通过多线程,或用现成的爬虫框架之类等等等。读者请自行思考完善。当然,如果你想留邮箱的话。。不先去start下?:)
完。