在之前一篇抓取漫画图片的文章里,通过实现一个简单的Python程序,遍历所有漫画的url,对请求所返回的html源码进行正则表达式分析,来提取到需要的数据。
本篇文章,通过 scrapy 框架来实现相同的功能。scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架。关于框架使用的更多详情可浏览官方文档,本篇文章展示的是爬取漫画图片的大体实现过程。
scrapy环境配置
安装
首先是 scrapy 的安装,博主用的是Mac系统,直接运行命令行:
pip install Scrapy
对于html节点信息的提取使用了 Beautiful Soup 库,大概的用法可见之前的一篇文章,直接通过命令安装:
pip install beautifulsoup4
对于目标网页的 Beautiful Soup 对象初始化需要用到 html5lib 解释器,安装的命令:
pip install html5lib
安装完成后,直接在命令行运行命令:
scrapy
可以看到如下输出结果,这时候证明scrapy安装完成了。
Scrapy 1.2.1 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
commands
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
...
项目创建
通过命令行在当前路径下创建一个名为 Comics 的项目
scrapy startproject Comics
创建完成后,当前目录下出现对应的项目文件夹,可以看到生成的Comics文件结构为:
|____Comics
| |______init__.py
| |______pycache__
| |____items.py
| |____pipelines.py
| |____settings.py
| |____spiders
| | |______init__.py
| | |______pycache__
|____scrapy.cfg
Ps. 打印当前文件结构命令为:
find . -print | sed -e 's;[^/]*/;|____;g;s;____|; |;g'
每个文件对应的具体功能可查阅官方文档,本篇实现对这些文件涉及不多,所以按下不表。
创建Spider类
创建一个用来实现具体爬取功能的类,我们所有的处理实现都会在这个类中进行,它必须为 scrapy.Spider 的子类。
在 Comics/spiders 文件路径下创建 comics.py 文件。
comics.py 的具体实现:
#coding:utf-8
import scrapy
class Comics(scrapy.Spider):
name = "comics"
def start_requests(self):
urls = ['http://www.xeall.com/shenshi']
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
self.log(response.body);
自定义的类为scrapy.Spider的子类,其中的name属性为该爬虫的唯一标识,作为scrapy爬取命令的参数。其他方法的属性后续再解释。
运行
创建好自定义的类后,切换到Comics路径下,运行命令,启动爬虫任务开始爬取网页。
scrapy crawl comics
打印的结果为爬虫运行过程中的信息,和目标爬取网页的html源码。
2016-11-26 22:04:35 [scrapy] INFO: Scrapy 1.2.1 started (bot: Comics)
2016-11-26 22:04:35 [scrapy] INFO: Overridden settings: {'ROBOTSTXT_OBEY': True, 'BOT_NAME': 'Comics', 'NEWSPIDER_MODULE': 'Comics.spiders', 'SPIDER_MODULES': ['Comics.spiders']}
2016-11-26 22:04:35 [scrapy] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
...
此时,一个基本的爬虫创建完成了,下面是具体过程的实现。
爬取漫画图片
起始地址
爬虫的起始地址为:
http://www.xeall.com/shenshi
我们主要的关注点在于页面中间的漫画列表,列表下方有显示页数的控件。如下图所示
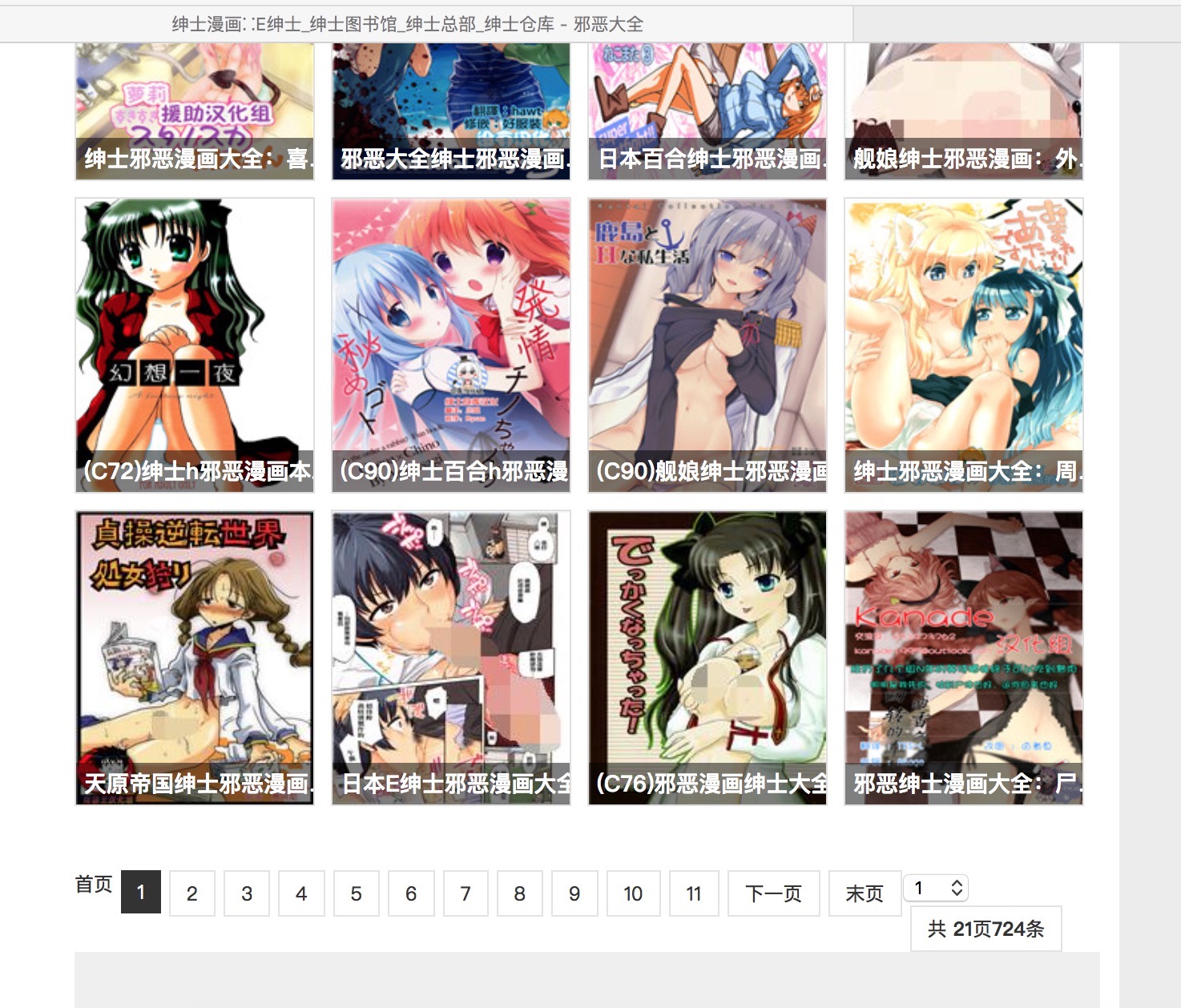
爬虫的主要任务是爬取列表中每一部漫画的图片,爬取完当前页后,进入下一页漫画列表继续爬取漫画,依次不断循环直至所有漫画爬取完毕。
起始地址的url我们放在了start_requests函数的urls数组中。其中start_requests是重载了父类的方法,爬虫任务开始时会执行到这个方法。
start_requests方法中主要的执行在这一行代码:请求指定的url,请求完成后调用对应的回调函数self.parse
scrapy.Request(url=url, callback=self.parse)
对于之前的代码其实还有另一种实现方式:
#coding:utf-8
import scrapy
class Comics(scrapy.Spider):
name = "comics"
start_urls = ['http://www.xeall.com/shenshi']
def parse(self, response):
self.log(response.body);
start_urls是框架中提供的属性,为一个包含目标网页url的数组,设置了start_urls的值后,不需要重载start_requests方法,爬虫也会依次爬取start_urls中的地址,并在请求完成后自动调用parse作为回调方法。
不过为了在过程中方便调式其它的回调函数,demo中还是使用了前一种实现方式。
爬取漫画url
从起始网页开始,首先我们要爬取到每一部漫画的url。
当前页漫画列表
起始页为漫画列表的第一页,我们要从当前页中提取出所需信息,动过实现回调parse方法。
在开头导入BeautifulSoup库
from bs4 import BeautifulSoup
请求返回的html源码用来给BeautifulSoup初始化。
def parse(self, response):
content = response.body;
soup = BeautifulSoup(content, "html5lib")
初始化指定了html5lib解释器,若没安装这里会报错。BeautifulSoup初始化时若不提供指定解释器,则会自动使用自认为匹配的最佳解释器,这里有个坑,对于目标网页的源码使用默认最佳解释器为lxml,此时解析出的结果会有问题,而导致无法进行接下来的数据提取。所以当发现有时候提取结果又问题时,打印soup看看是否正确。
查看html源码可知,页面中显示漫画列表的部分为类名为listcon的ul标签,通过listcon类能唯一确认对应的标签
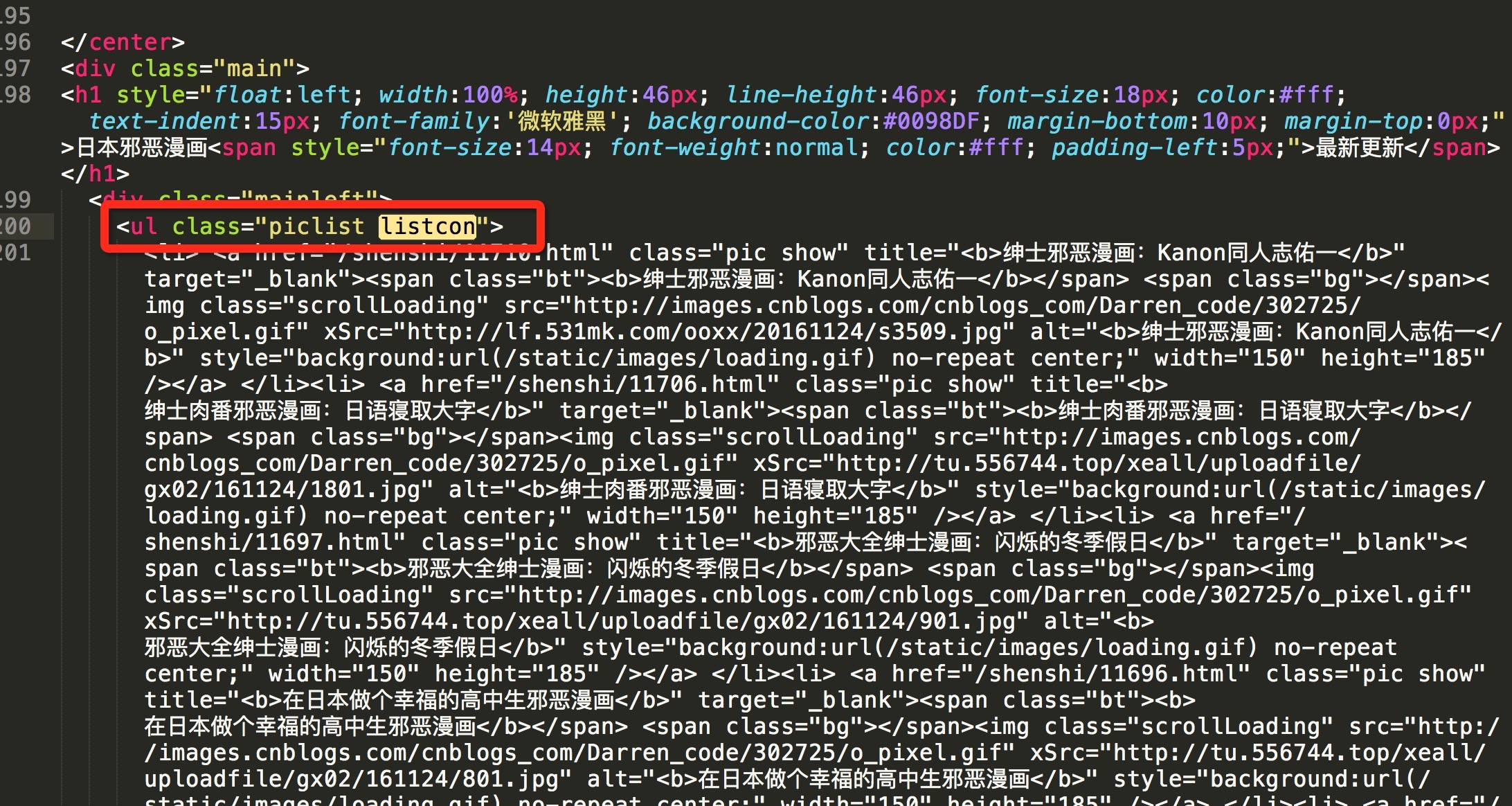
提取包含漫画列表的标签
listcon_tag = soup.find('ul', class_='listcon')
上面的find方法意为寻找class为listcon的ul标签,返回的是对应标签的所有内容。
在列表标签中查找所有拥有href属性的a标签,这些a标签即为每部漫画对应的信息。
com_a_list = listcon_tag.find_all('a', attrs={'href': True})
然后将每部漫画的href属性合成完整能访问的url地址,保存在一个数组中。
comics_url_list = []
base = 'http://www.xeall.com'
for tag_a in com_a_list:
url = base + tag_a['href']
comics_url_list.append(url)
此时comics_url_list数组即包含当前页每部漫画的url。
下一页列表
看到列表下方的选择页控件,我们可以通过这个地方来获取到下一页的url。
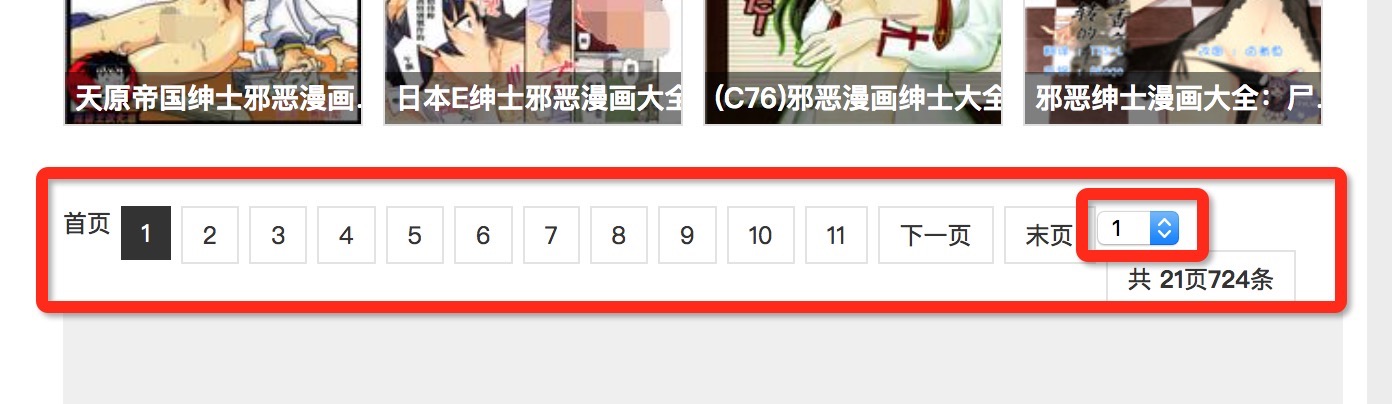
获取选择页标签中,所有包含href属性的a标签
page_tag = soup.find('ul', class_='pagelist')
page_a_list = page_tag.find_all('a', attrs={'href': True})
这部分源码如下图,可看到,所有的a标签中,倒数第一个代表末页的url,倒数第二个代表下一页的url,因此,我们可以通过取page_a_list数组中倒数第二个元素来获取到下一页的url。
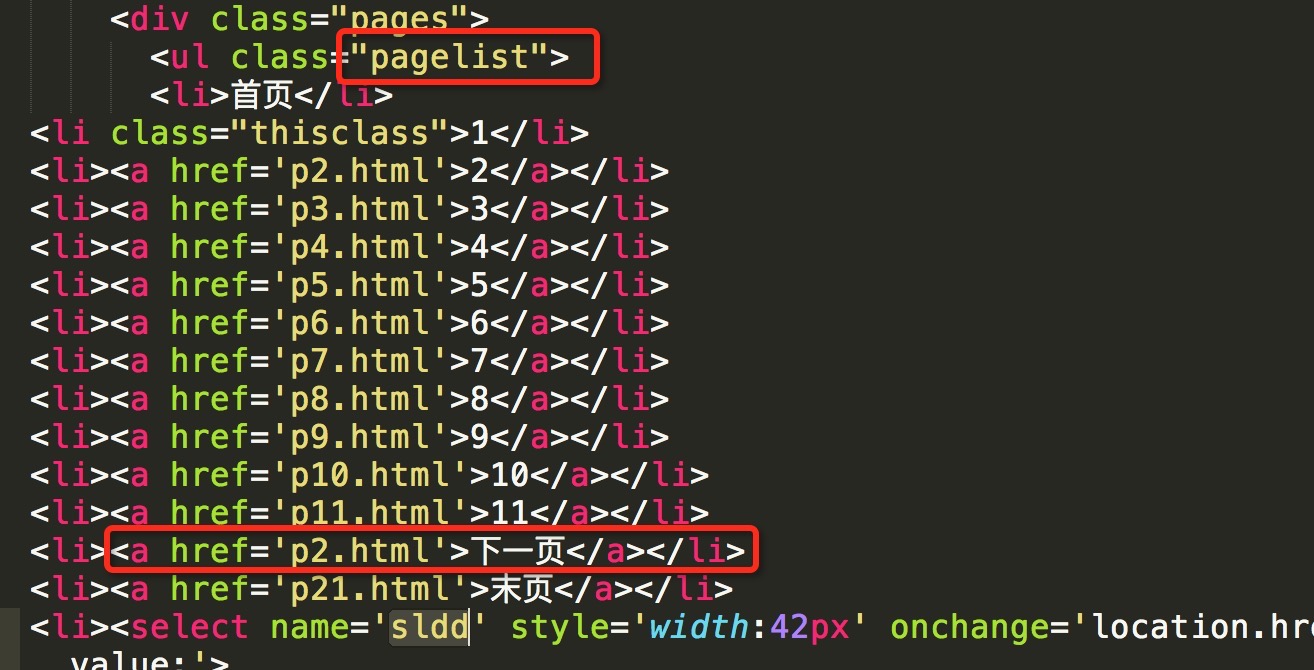
但这里需要注意的是,若当前为最后一页时,不需要再取下一页。那么如何判断当前页是否是最后一页呢?
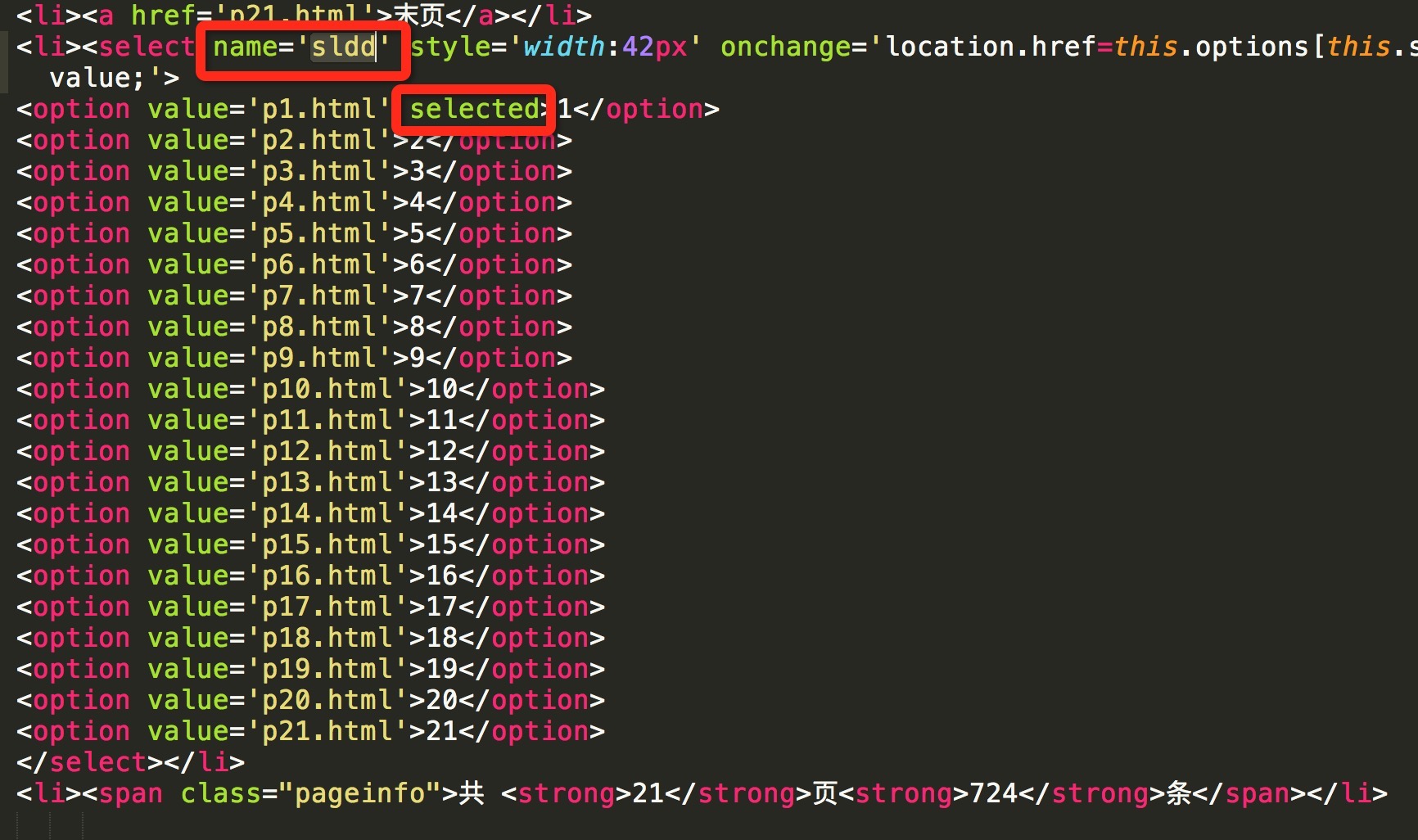
可以通过select控件来判断。通过源码可以判断,当前页对应的option标签会具有selected属性,下图为当前页为第一页
下图为当前页为最后一页
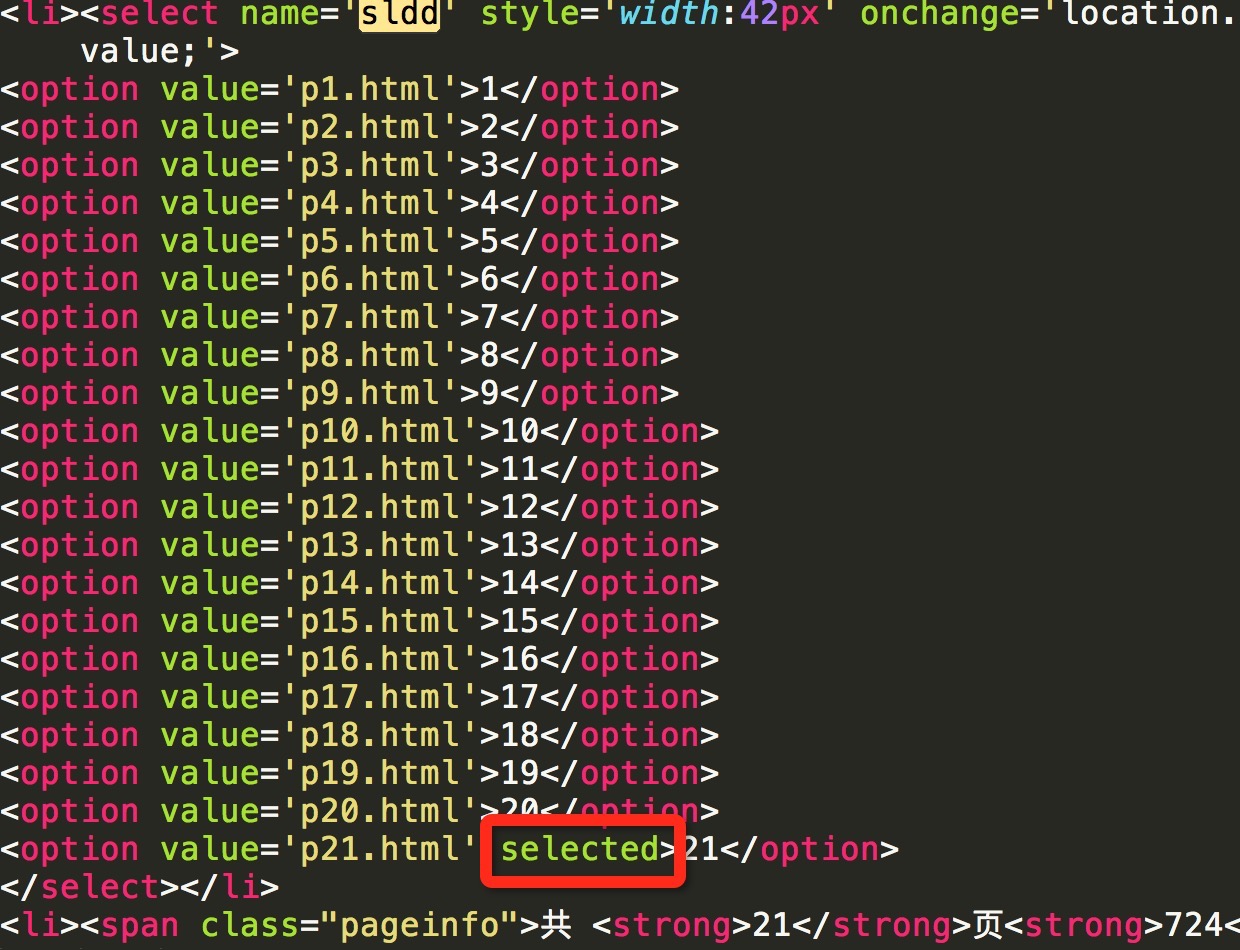
通过当前页数与最后一页页数做对比,若相同则说明当前页为最后一页。
select_tag = soup.find('select', attrs={'name': 'sldd'})
option_list = select_tag.find_all('option')
last_option = option_list[-1]
current_option = select_tag.find('option' ,attrs={'selected': True})
is_last = (last_option.string == current_option.string)
当前不为最后一页,则继续对下一页做相同的处理,请求依然通过回调parse方法做处理
if not is_last:
next_page = 'http://www.xeall.com/shenshi/' + page_a_list[-2]['href']
if next_page is not None:
print('\n------ parse next page --------')
print(next_page)
yield scrapy.Request(next_page, callback=self.parse)
通过同样的方式依次处理每一页,直到所有页处理完成。
爬取漫画图片
在parse方法中提取到当前页的所有漫画url时,就可以开始对每部漫画进行处理。
在获取到comics_url_list数组的下方加上下面代码:
for url in comics_url_list:
yield scrapy.Request(url=url, callback=self.comics_parse)
对每部漫画的url进行请求,回调处理方法为self.comics_parse,comics_parse方法用来处理每部漫画,下面为具体实现。
当前页图片
首相将请求返回的源码构造一个BeautifulSoup,和前面基本一致
def comics_parse(self, response):
content = response.body;
soup = BeautifulSoup(content, "html5lib")
提取选择页控件标签,页面显示和源码如下所示
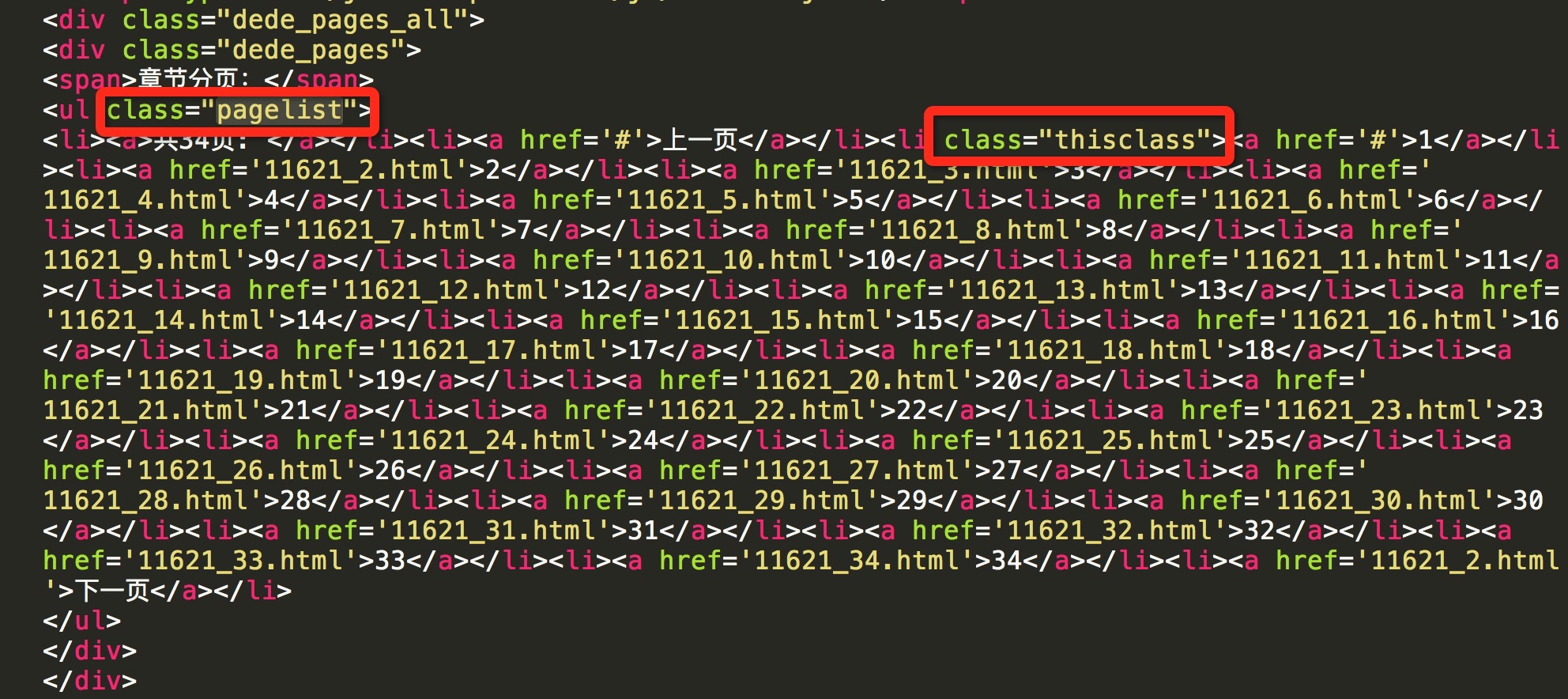
提取class为pagelist的ul标签
page_list_tag = soup.find('ul', class_='pagelist')
查看源码可以看到当前页的li标签的class属性thisclass,以此获取到当前页页数
current_li = page_list_tag.find('li', class_='thisclass')
page_num = current_li.a.string
当前页图片的标签和对应源码
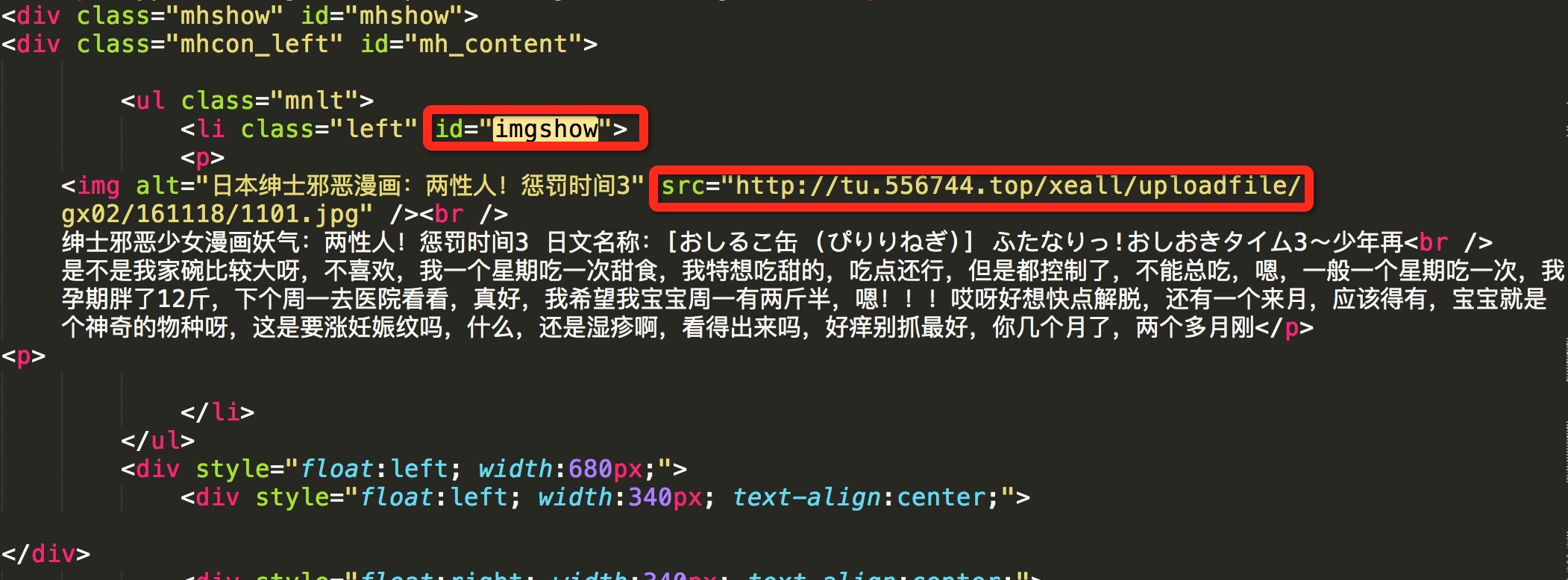
获取当前页图片的url,以及漫画的标题。漫画标题之后用来作为存储对应漫画的文件夹名称。
li_tag = soup.find('li', id='imgshow')
img_tag = li_tag.find('img')
img_url = img_tag['src']
title = img_tag['alt']
保存到本地
当提取到图片url时,便可通过url请求图片并保存到本地
self.save_img(page_num, title, img_url)
定义了一个专门用来保存图片的方法save_img,具体完整实现如下
# 先导入库
import os
import urllib
import zlib
def save_img(self, img_mun, title, img_url):
# 将图片保存到本地
self.log('saving pic: ' + img_url)
# 保存漫画的文件夹
document = '/Users/moshuqi/Desktop/cartoon'
# 每部漫画的文件名以标题命名
comics_path = document + '/' + title
exists = os.path.exists(comics_path)
if not exists:
self.log('create document: ' + title)
os.makedirs(comics_path)
# 每张图片以页数命名
pic_name = comics_path + '/' + img_mun + '.jpg'
# 检查图片是否已经下载到本地,若存在则不再重新下载
exists = os.path.exists(pic_name)
if exists:
self.log('pic exists: ' + pic_name)
return
try:
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
req = urllib.request.Request(img_url, headers=headers)
response = urllib.request.urlopen(req, timeout=30)
# 请求返回到的数据
data = response.read()
# 若返回数据为压缩数据需要先进行解压
if response.info().get('Content-Encoding') == 'gzip':
data = zlib.decompress(data, 16 + zlib.MAX_WBITS)
# 图片保存到本地
fp = open(pic_name, "wb")
fp.write(data)
fp.close
self.log('save image finished:' + pic_name)
except Exception as e:
self.log('save image error.')
self.log(e)
函数主要用到3个参数,当前图片的页数,漫画的名称,图片的url。
图片会保存在以漫画名称命名的文件夹中,若不存在对应文件夹,则创建一个,一般在获取第一张图时需要自主创建一个文件夹。
document为本地指定的文件夹,可自定义。
每张图片以页数.jpg的格式命名,若本地已存在同名图片则不再进行重新下载,一般用在反复开始任务的情况下进行判断以避免对已存在图片进行重复请求。
请求返回的图片数据是被压缩过的,可以通过response.info().get('Content-Encoding')的类型来进行判断。压缩过的图片要先经过zlib.decompress解压再保存到本地,否则图片打不开。
大体实现思路如上,代码中也附上注释了。
下一页图片
和在漫画列表界面中的处理方式类似,在漫画页面中我们也需要不断获取下一页的图片,不断的遍历直至最后一页。
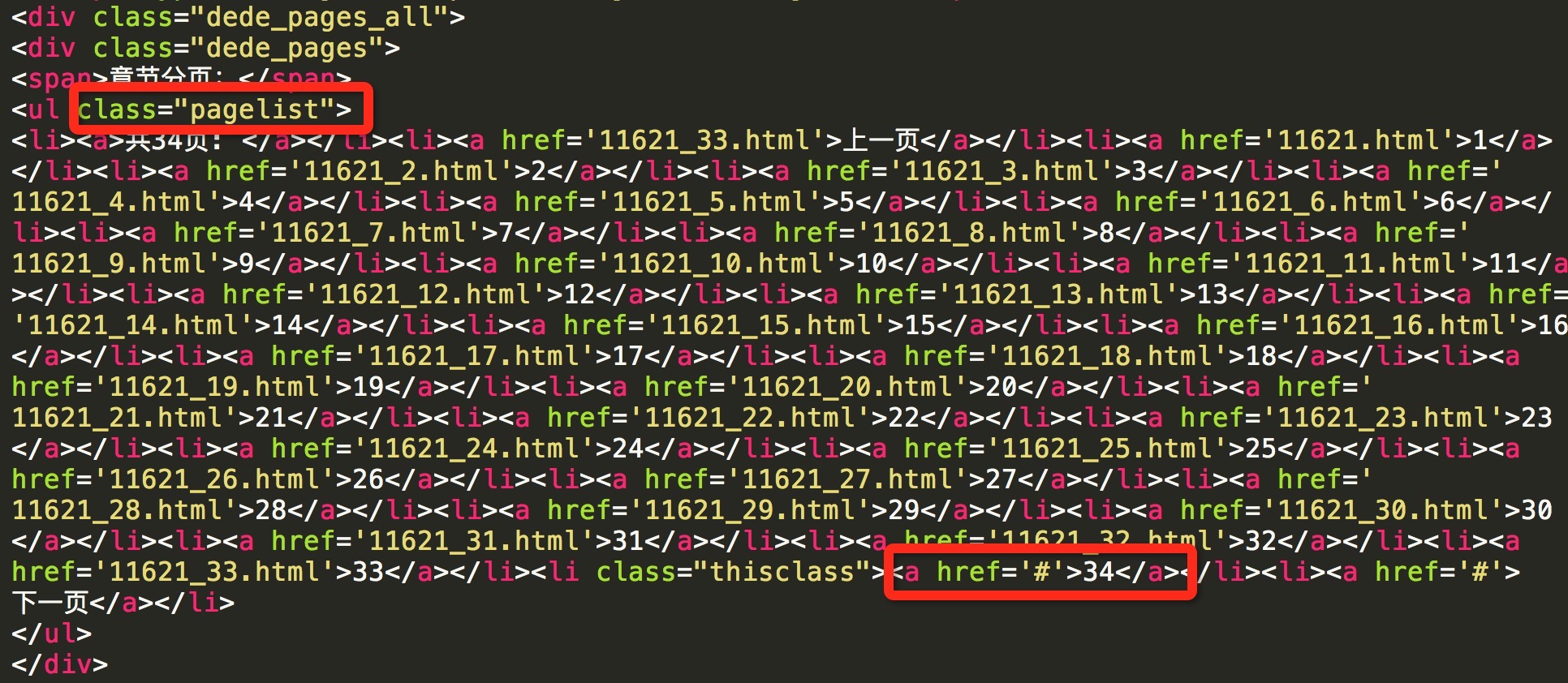
当下一页标签的href属性为#时为漫画的最后一页
a_tag_list = page_list_tag.find_all('a')
next_page = a_tag_list[-1]['href']
if next_page == '#':
self.log('parse comics:' + title + 'finished.')
else:
next_page = 'http://www.xeall.com/shenshi/' + next_page
yield scrapy.Request(next_page, callback=self.comics_parse)
若当前为最后一页,则该部漫画遍历完成,否则继续通过相同方式处理下一页
yield scrapy.Request(next_page, callback=self.comics_parse)
运行结果
大体的实现基本完成,运行起来,可以看到控制台打印情况
本地文件夹保存到的图片
scrapy框架运行的时候使用了多线程,能够看到多部漫画是同时进行爬取的。
目标网站资源服务器感觉比较慢,会经常出现请求超时的情况。跑的时候请耐心等待。:)
最后
本文介绍的只是scrapy框架非常基本的用法,还有各种很细节的特性配置,如使用FilesPipeline、ImagesPipeline来保存下载的文件或者图片;框架本身自带了个XPath类用来对网页信息进行提取,这个的效率要比BeautifulSoup高;也可以通过专门的item类将爬取的数据结果保存作为一个类返回。具体请查阅官网。
最后附上完整Demo源码,如果我告诉你其实目标网站是福利你会给个star么?-_-

完。